
Bespuća transliteracije
Ovde ćemo pokušati da damo nekoliko informacija na koji način je moguće pristupiti problemu konverzije postojećih tekstova iz latinice u ћирилицу i obratno.
Oni koji se malo duže bave računarima, sećaju se vremena kada je uključivanje naših karaktera u računarski generisane tekstove bio pravi izazov. U jednom momentu jednostavno nije bilo definisanih standardnih kodnih strana za srpsko ćirilično i latinično pismo a fontovi koji su bili na raspolaganju nisu pokrivali kompletan spektar kodnih znakova, te su umesto naših znakova (čćžšđ) najčešće izbacivali raznorazne kukice, kvačice i sl. Prvobitne kodne strane (ASCII), s obzirom na mesto nastanka, bile su isključivo fokusirane na englesku latinicu i set dodatnih znakova neophodnih u procesu programiranja i interpunkcijskih znakova. Prva verzija ASCII bila je 7-bitna i imala je mesta za definisanje ukupno 128 znakova. U drugoj reviziji prešlo se na 8-bitnu (1 bajt) tabelu koja je davala mogućnost definisanja 256 znakova. Prikazivanje slova i znakova iz drugih jezika rešavano je na način da su sekvencijalno definisane kodne strane koje su sadržavale znakove neophodne za prikaz svih karaktera ciljnih jezika (Latin1 (ISO-8859-1), Latin2 (ISO-8859-2), Windows-1250 (konačno naša latinica), ISO-8859-5, KOI8-R, Windows-1251 (i konačno naša ćirilica)…). Ove kodne strane su zadržale isti broj karaktera kao druga verzija ASCII standarda – 8 bita iliti 256 karaktera. Ono što je urađeno je da su neki znaci (kodovi u tabeli) jednostavno deklarisani da označavaju nedostajuća ćirilična i latinična slova iz našeg alfabeta / azbuke. Posledica ovoga je bila ta da su morali postojati fontovi koji su bili prilagođeni odgovarajućim kodnim stranama, a u vreme do definisanja ovih standarda, ljudi na ovim prostorima su se dovijali na razne načine da ostvare primarni cilj u pisanju dokumenata i pripremi za štampu, te se u nekom trenutku pojavilo i nekoliko nezvaničnih „standarda“ za kodne strane za srpskohrvatsku latinicu / ćirilicu. Ovo je iziskivalo upotrebu fontova koji su namenski i ručno modifikovani da odgovaraju ovim modifikovanim kodnim stranama, te se prilikom razmene dokumenata, u to doba dešavale danas nezamislive stvari da kompletan otvoren tekst u Word jednostavno više nije prepoznatljiv i da nije moguće njegovo čitanje. Često je najlakši način rada sa ovakvim dokumentima iziskivao nalaženje originalnih fontova koji su korišćeni prilikom njihovog kreiranja.
nekada je osisana latinica bila jedini izbor. nemojte biti toliko osudjujuci
Pojavom Unicode standarda većina ovih tehničkih problema je prevaziđena. Unicode koristi 16-bitnu tabelu koja dozvoljava definisanje 2^16 = 65536 znakova što je dovoljno da pokrije sve danas poznate znakove svih poznatih jezika i pisama. Danas srećom, sem u situacijama kada se „naleti“ na stariji dokumenat (ili kada imate sreću da radite sa predstavnicima stare garde koji ne haju za tehnološki napredak ostvaren u zadnjih par decenija), nemile scene iz prethodnog teksta nisu toliko česte i velika je verovatnoća da oni koji su uključeni u računarski svet u zadnjoj deceniji neće imati priliku da se sretnu sa sličnim problemima. uz svaki moderni operativni sistem, standardno se isporučuje set fontova koji garantovano pokriva celokupan opseg Unicode standarda (UTF-16 revizije) – korišćenjem Arial, Times New Roman, Calibri ili sličnih fontova, imate garanciju da se nećete susretati sa problemima gore navedenim.
Mi kao nacija, naravno, imamo još jedan izazov, a to je da imamo sreću (ili nesreću) da uglavnom ravnopravno koristimo i ćirilično i latinično pismo u svakodnevnom životu, pa da vidimo kako je moguće iskoristiti tehnologiju koja nam je dostupna da postojeće tekstove prebacimo iz jednog u drugo pismo kada se za to javi potreba. Da priču krenemo vezano za Unicode. Da pomenem- ako iz prethodnog teksta niste izvukli zaključak, svaki karakter u nekom dokumentu, računar čuva i u formi adrese iz Unicode tabele. Da biste vi videli na ekranu ili papiru ono što prepoznajete kao slovo ili znak interpunkcije, najbanalnije objašnjeno, računar pronađe u fontu koji koristite znak koji odgovara tom kodu i prikaže ga na ekranu ili pošalje na štampu. Konverzija nekog slova iz jednog u drugo pismo predstavlja relativno jednostavan zadatak da se za svaki pojedinačan karakter izvrši zamena njegovog koda koji odgovara jednom pismu, odgovarajućim kodom iz drugog pisma. Ovo predstavlja relativno jednostavan programerski zadatak i postoji veliki broj, što programa što web strana koji su u stanju da odrade ovaj posao za vas. Da nabrojim neke
Stand alone programi i MS Word add-on
Microsoft Transliteration utility
https://www.microsoft.com/en-us/download/details.aspx?id=17933
Transliterator
https://store.office.com/addinstemplateinstallpage.aspx?rs=en-NZ&assetid=WA104379177
Cir-Latin
http://milos.djekic.net/my-software/cir-latin/
TranslitGT
https://alberoart.com/translitgt-add-in/#
Web strane
http://konvertor.co.rs
http://www.preslovljavanje.com
E sad…
Sve ovo gore navedeno omogućava vam relativno jednostavne operacije transliteracije i to pod uslovom da su tekstovi koje obrađujete urađenu u Unicode. Međutim, ukoliko radite sa nekim starijim tekstom originalno uređenim u nekoj starijoj kodnoj strani, ovi alati su uglavnom beskorisni i biće vam potrebno nešto što se zove konvertor kodnih strana. Srećom, rešenje postoji. Jedno vreme, alat izbora za ovaj posao bio je „Yu konvertor 98“ – makro urađen u Word-u koji je omogućavao veoma uspešnu konverziju između svih kodnih rasporeda korišćenih na prostoru bivše zajedničke države. Alat je uspešno održavan do početka 2000-ih, a kasnije se pojavila njegova zamena u vidu alata YuCirLat ’08.
http://www.praktikum.rs/office/word/yucirlat08.asp
U pitanju je Add-on za MS Word koji se instalira iz dokumenta koji se može skinuti sa linkovane strane.
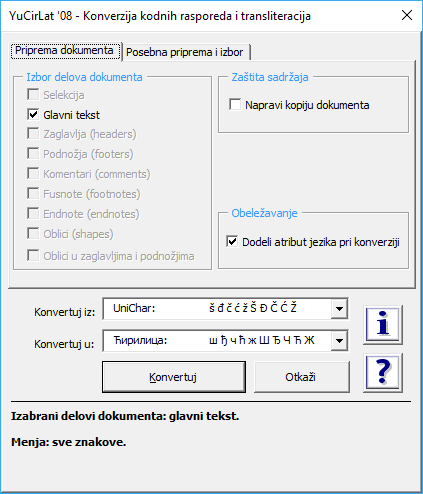
Ovaj alat je zadržao kompletnu funkcionalnost sadržanu u „Yu konvertor 98“ i dodao nekoliko dodatnih opcija koje znaju biti veoma korisne i upotrebljivost samog alata stvarno dižu na viši nivo. Nećemo ovde pokušavati da pravimo uputstvo za rad sa ovim alatom – add-on je delo domaćih autora, postoje uputstvana srpskom jeziku a u paketu dostupnom za skidanje, autori su spakovali i nekoliko dokumenata koji omogućavaju uvežbavanje rada. Ja bi ovde samo da pomenem neke stvari koje mislim da slikovito mogu da objasne kvalitet i upotrebljivost ovog alata. Naime, moguće je izvršiti izbor delova teksta nad kojima će se vršiti konverzija (glavni tekst, zaglevlje, fusnote…), moguće je konverziju ograničiti na delove teksta kojime je dodeljen atribut da su napisani na srpskom jeziku, moguće je delove teksta sa određenim formatiranjem izostaviti iz konverzije…uglavnom, sa ovim alatom, moguće je in-situ, izvršiti konverziju kompletnog Word dokumenta iz npr. latinice u ćirilicu uz izostavljanje stranih reči i izraza iz konverzije, izostavljanje npr. oznaka fizičkih veličina iz konverzije i slično. korišćenje “YuCirLat ’08” nije baš najintuitivnije moguće, te je potrebno provesti izvesno vreme u shvatanju tehnologije rada na način kako je to kreator zamislio, ali onome ko ima potrebu da se bavi ovakvim zadacima, to vreme će se sigurno isplatiti i ovaj alat će sigurno uštedeti značajnu količinu vremena i poštedeti ga ozbiljne glavobolje.
Srećno preslovljavanje
PS
Gornji deo teksta otprilike pokriva kompletno ovu tematiku transliteracije između ćiriličnog i latiničnog pisma. Ovde samo imam želju da podelim sopstvenu frustraciju vezanu za način kako se ovoj temi prilazi u našem društvu. Problem praktične upotrebe našeg pisma u kompjuterskom svetu ima dve komponente; tekst iznad se bavi standardizacijom kodnih rasporeda, a druga komponenta je vezana za fizički interfejs koji koristimo u svrhu unosa teksta – tastaturi. Slično kao u doba kreacije „custom“ kodnih rasporeda za latinicu i ćirilicu, problem tastatura za unos karaktera srpskog jezika rešen je na način da se pošlo od layout-a kreiranog za upotrebu engleskog jezika, te se prostom izmenom pojedinih tastera došlo do ovog današnjeg „frankenštajna“ koji nazivamo srpskom (ili hrvatskom, ili bosanskom…) tastaturom. S obzirom da se koristi isti broj tastera, a nama efektivno treba 5 znakova više, jasno je da su neki karakteri morali biti žrtvovani kako bi se zadovoljila minimalna potrebna funkcija. Na slici dole može da se vidi razlika između ANSI standarda i modifikacije istog standarda za rad sa srpskom ćirilicom.
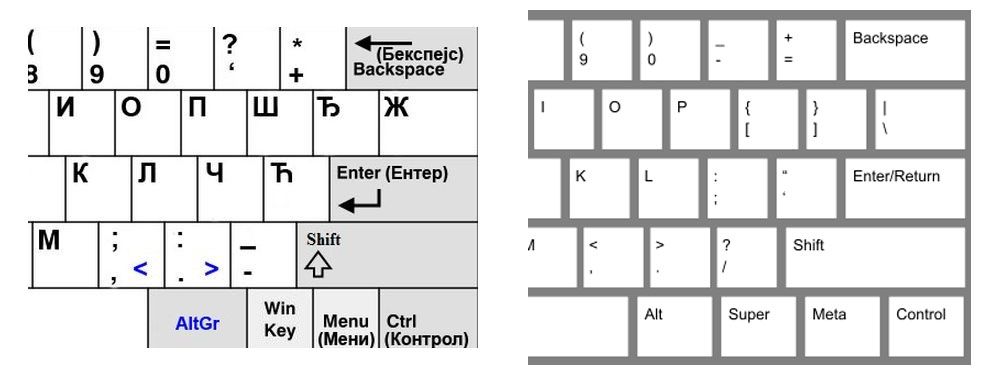
Karakteri koji su „žrtvovani“ su ili sklonjeni na druge pozicije, ili su rešeni na način da je potrebno koristiti „Alt Gr“ modifikator kako bi se omogućio njihov unos. Ovo u praksi ima reperkusije tipa da dan danas nemali broj ljudi prebacuje tastaturu u engleski raspored kako bi uneli znak „@“ neophodan u email komunikaciji. „Ctrl-Z“ kombinacija koja predstavlja univerzalnu skraćenicu za poništavanje zadnje komande (Undo) je praktično neupotrebljiva jer je karakter „Z“ prebačen u sredinu tastature. Karakteri smešteni oko tastera „Enter“ možda nemaju značajnu korisnu vrednost u pisanju tekstova, ali su nezamenljivi i beskrajno važni za sve koji rade kao sistem administratori, administratori kompjuterskih mreža ili se bave programiranjem. Dislokacija ovih karaktera čini njihov rad sa tastaturom nekoliko puta komplikovanijim i nije retka situacija da oni koji imaju potrebu da se bave ovim poslovima jednostavno beže od srpske tastature „ko đavo od krsta“.
Ja se samo nadam da će nekom „jezičkom talibanu“ što propoveda zaštitu našeg pisma u moderno vreme, konačno pasti na pamet da se pozabavi pitanjem ergonomije srpske tastature. Krajnje vreme bi bilo da se kreira nekakav srpski standardni raspored koji će ovom problemu prići sa pozicije dodavanja nedostajućih 5 karaktera uz zadržavanje pune funkcionalnosti i upotrebljivosti ANSI (ili ISO) rasporeda, umesto sa pozicije uništavanja istog. Malo raditi pametno. Ne mora sve na mišiće. Nada zadnja umire. Do tada…jbg, patnja.




